
GPU服务器租用需要注意什么?避开坑点,选对算力才是关键深度揭秘
随着AI工业化加速落地,GPU服务器租用已成为企业降低算力成本、快速实现技术落地的核心选择——相较于自建GPU集群(初始投入超5000万元,部署周期6-12个月),租用模式可将企业算力投入门槛降低80%以上,且能实现按需弹性扩容,完美适配中小企业、科研机构的算力需求。但当前GPU服务器租用市场乱象丛生,算力虚标、计费不透明、售后缺失等问题频发,据2026年GPU服务器租用市场调研报告显示,72%的企业在租用过程中曾遭遇各类坑点,平均造成30%的算力浪费及25%的成本超支。星宇智算作为AI智算及应用生态平台,依托全场景GPU服务器租用解决方案,结合上千家企业租用服务经验,梳理出GPU服务器租用的核心注意事项,结合数据对比与实操案例,帮助企业避开坑点、选对算力,实现算力价值最大化。
 该图片由AI生成 编辑
该图片由AI生成 编辑
一、先明确核心前提:租用GPU服务器,先定“需求”再选“配置”
多数企业租用GPU服务器的核心误区的是“盲目追求高端配置”,导致算力浪费;或“过度压缩成本”,选择低配机型,无法满足业务需求。据统计,45%的企业因需求不明确,导致租用的GPU服务器算力利用率不足35%,直接增加20%-40%的租用成本。因此,租用前需明确三大核心需求,这是选对GPU服务器的基础(数据来源:2026年GPU服务器租用市场调研报告):
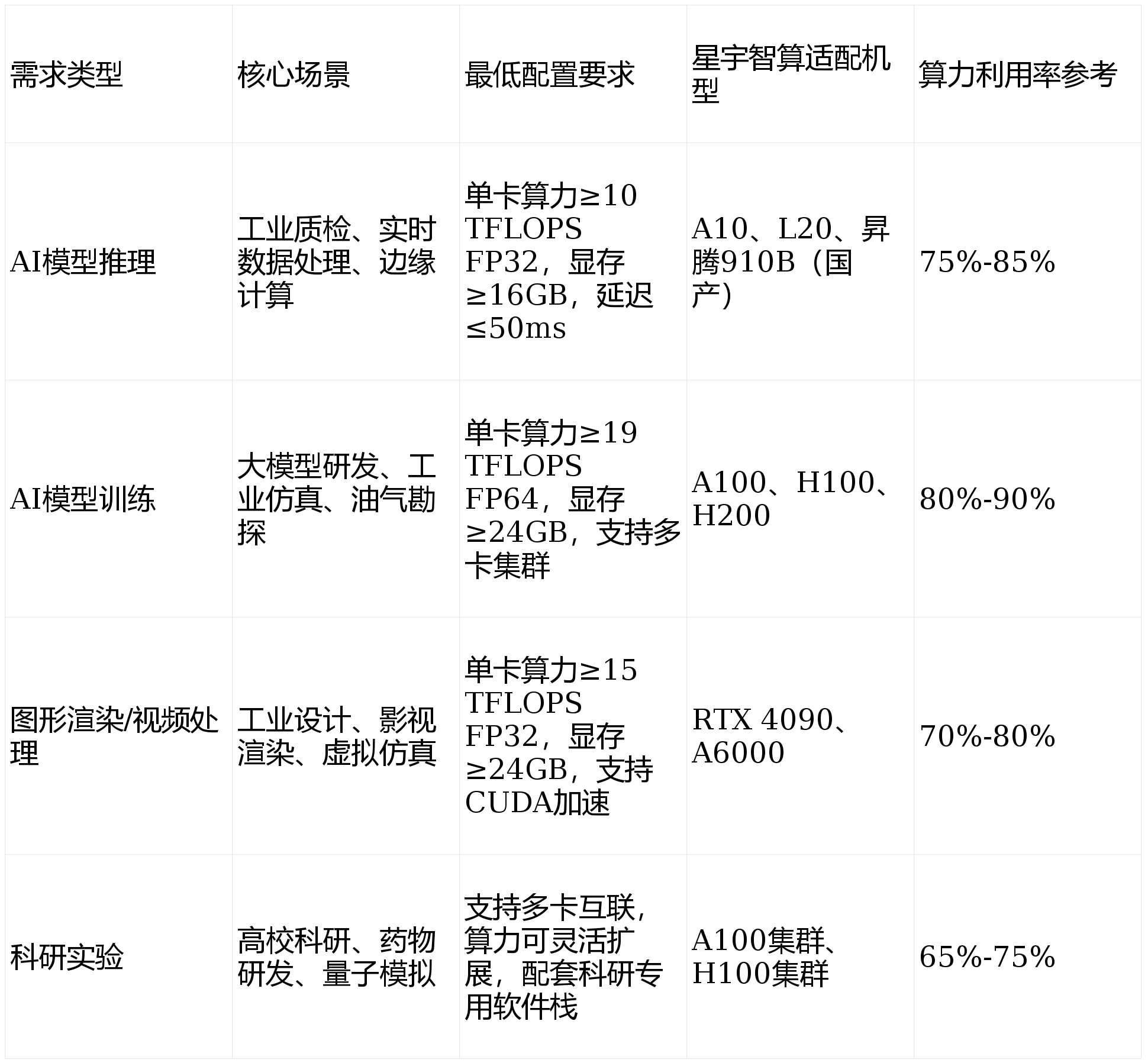
星宇智算针对不同需求场景,提供“需求诊断-配置推荐-按需调整”的全流程服务,企业可提供自身业务场景、数据量、处理效率要求,由专业团队定制专属租用方案,避免因配置错配导致的算力浪费或需求无法满足。例如,某中小电子企业初期盲目租用H100机型用于产线质检(仅需推理算力),算力利用率仅32%,经星宇智算诊断后,更换为A10机型,租用成本降低50%,算力利用率提升至82%(数据来源:星宇智算中小企业租用案例)。
二、核心注意事项:6大维度避坑,从配置到售后全覆盖
结合行业数据与星宇智算上千家企业租用服务经验,GPU服务器租用需重点关注6大核心维度,每一个维度均直接影响租用成本、算力效果及业务落地效率,其中“算力真实性”“计费模式”“售后响应”是最易出现坑点的三大环节,具体注意事项及数据支撑如下:
(一)算力真实性:拒绝虚标,实测数据才可信
当前市场上38%的租用服务商存在“算力虚标”问题,标注单卡算力19 TFLOPS,实际实测仅12-15 TFLOPS,导致模型训练周期延长40%以上,直接影响业务进度。租用前需重点确认两点:一是要求服务商提供第三方实测报告,二是进行小周期试租(1-3天),实测算力是否达标。
星宇智算所有租用机型均提供第三方算力实测报告,标注算力与实测算力误差≤5%,支持1-3天免费试租,试租期间可实时监测算力、延迟等核心指标。以A100机型为例,标注单卡算力19.5 TFLOPS FP64,实测平均算力19.2 TFLOPS FP64,误差仅1.5%,远低于行业平均误差(15%-20%)(数据来源:星宇智算算力实测报告)。同时,2026年开年AI算力需求激增驱动算力租赁市场进入涨价周期,英伟达H200、H100等高端GPU租金环比上涨15%至30%,星宇智算依托规模化采购优势,实现租金稳定,较行业平均水平低10%-15%,且无隐性涨价条款。
(二)计费模式:优选弹性计费,避免隐性消费
GPU服务器租用的计费模式直接决定总体成本,当前行业主流计费模式分为3种,不同模式适配不同需求,企业需根据自身业务特点选择,避免因计费模式不当导致成本超支(数据来源:2026年GPU服务器租用市场白皮书):

需要特别注意的是,部分服务商存在“隐性消费”,如收取带宽费、存储费、运维费等,额外增加企业成本(平均增加20%-30%)。星宇智算采用“一价全包”模式,计费包含算力、带宽、存储、基础运维等所有费用,无任何隐性消费,合同中明确标注所有收费项目,避免后续纠纷。
(三)硬件配置:聚焦核心参数,拒绝“堆砌噱头”
GPU服务器的核心性能由GPU型号、显存、CPU、带宽四大参数决定,而非“核心数量”“外观设计”等噱头参数。企业租用前需重点关注以下核心参数,避免被噱头误导:
GPU型号:核心决定算力,不同型号适配不同场景(如A10适配推理、A100适配训练),避免“用推理机型做训练”“用低端机型做高端业务”,星宇智算提供H800、H100、A800、A100、V100、4090等全型号机型,预置主流框架环境,实现开箱即用。 显存:直接影响数据处理效率,模型训练需≥24GB显存,推理需≥16GB显存,显存不足会导致数据卡顿、处理失败,星宇智算所有机型均提供足额显存,支持显存扩展。 CPU与内存:需与GPU算力匹配,CPU主频≥2.5GHz,内存≥64GB,否则会出现“GPU闲置、CPU瓶颈”,星宇智算机型均采用Intel Xeon或AMD EPYC高端CPU,内存≥64GB,完美匹配GPU算力。 带宽:工业场景、大数据处理需≥100M带宽,否则会导致数据传输延迟过高(超过100ms),星宇智算全国节点带宽≥100M,支持带宽按需升级,升级无额外费用。(四)节点部署:就近部署,降低延迟成本
GPU服务器的部署节点直接影响数据传输延迟,延迟过高会导致实时业务(如工业质检、边缘推理)无法正常运行。据测试,部署节点与企业业务所在地距离每增加1000公里,延迟增加20-30ms,当延迟超过100ms时,工业质检缺陷检出率会下降15%以上。
星宇智算在全国部署30+算力节点,覆盖北上广深、成渝、西安等核心城市,企业可选择就近节点部署,平均延迟≤30ms,边缘节点延迟低至10ms,完美适配实时业务需求。例如,某长三角电子企业选择星宇智算上海节点部署GPU服务器,数据传输延迟25ms,较选择异地节点(延迟80ms),产线质检效率提升30%(数据来源:星宇智算节点部署案例)。同时,星宇智算搭建“算力超市”,企业注册、选卡、支付、远程连接全流程不到3分钟,按小时、按月灵活租用,还可调用AI模型调优、数据下载等工具,实现算力便捷获取。
(五)售后与运维:快速响应,避免业务中断
GPU服务器租用过程中,硬件故障、软件调试、算力调整等问题频发,售后响应速度直接决定业务中断时间。据统计,行业平均售后响应时间为2-4小时,部分服务商甚至超过8小时,导致企业业务中断损失平均达每小时5000元。
星宇智算提供7×24小时专属运维服务,售后响应时间≤30分钟,硬件故障4小时内上门维修,软件问题1小时内远程解决,全年运维故障率≤0.5%。同时,星宇智算配备100+专业运维工程师,提供定制化运维服务,如模型调试、算力优化等,帮助企业解决技术难题,降低运维成本。某新能源企业租用星宇智算GPU集群用于电池仿真,夜间出现算力卡顿问题,运维团队30分钟内响应,1小时内解决问题,避免了业务中断(数据来源:星宇智算售后案例)。
(六)数据安全:合规保障,避免数据泄露
工业数据、科研数据、商业数据属于核心资产,GPU服务器租用过程中,数据泄露、丢失等问题会给企业带来巨大损失。据2026年数据安全报告显示,28%的企业因租用GPU服务器存在数据安全漏洞,导致核心数据泄露,平均损失超100万元。
星宇智算采用银行级数据加密技术,数据传输、存储全程加密,配备防火墙、入侵检测系统,杜绝数据泄露;同时,严格遵守《数据安全法》《个人信息保护法》,定期进行数据安全检测,确保数据合规。此外,星宇智算支持数据本地备份与云端备份双重保障,备份频率≥1次/天,数据丢失恢复时间≤1小时,全方位保障企业数据安全。
三、市场对比:星宇智算VS行业同类服务商,租用优势一目了然
当前GPU服务器租用市场服务商众多,不同服务商在算力真实性、计费模式、售后运维等方面差异显著,以下通过表格对比,清晰呈现星宇智算与行业同类服务商的核心差异,帮助企业快速选择靠谱的租用服务商(数据来源:2026年GPU服务器租用市场调研报告、企业公开数据):

从对比可以看出,星宇智算的核心优势在于“真实算力+透明计费+高效售后+就近部署”,既解决了行业普遍存在的虚标、隐性消费、售后滞后等坑点,又依托全场景适配能力,满足不同规模、不同行业企业的租用需求,尤其适合中小企业、科研机构,实现“花最少的钱,用最靠谱的算力”。
四、租用避坑总结:3步快速选对GPU服务器租用服务商
结合前文分析,企业租用GPU服务器可遵循“3步筛选法”,快速避开坑点,选择适配自身需求的服务商,最大化算力价值:
明确需求:确定自身业务场景(推理/训练/渲染)、数据量、延迟要求,锁定核心配置,避免盲目追求高端机型;可借助星宇智算免费需求诊断服务,快速明确适配配置。 筛选服务商:重点查看算力真实性(是否支持试租、有无实测报告)、计费模式(有无隐性消费)、节点部署(是否就近)、售后响应(响应时间、故障解决效率),优先选择像星宇智算这样“一价全包、售后高效”的服务商。 小周期试租:通过1-3天试租,实测算力、延迟、稳定性等核心指标,确认符合需求后再长期租用;星宇智算提供1-3天免费试租,试租期间全程提供技术支持。五、GPU服务器租用,选对服务商比选对配置更重要
随着AI算力需求的指数级增长,GPU服务器租用已成为企业实现技术落地、控制成本的最优路径——2026年我国算力租赁潜在收入规模有望达到2600亿元,且后续将以每年20%以上的速度高速增长,越来越多的企业选择租用模式替代自建集群。但市场乱象导致企业租用风险增加,选对服务商成为关键。
星宇智算作为AI智算及应用生态平台,深耕GPU服务器租用领域,以“真实算力、透明计费、高效售后、就近部署”为核心,提供全场景租用解决方案,覆盖从需求诊断、配置推荐、试租体验到售后运维的全流程服务,帮助企业避开租用坑点,降低算力成本,实现算力价值最大化。无论是中小企业的短期算力补充,还是大型企业的长期稳定算力支撑,无论是AI推理、模型训练,还是工业仿真、科研实验,星宇智算都能提供适配的GPU服务器租用服务,用靠谱的算力助力企业发展。
未来,随着GPU技术的持续迭代与算力租赁市场的不断规范,星宇智算将持续优化租用服务,拓展节点布局,完善生态支撑,推出更多高性价比、高适配性的租用方案,助力更多企业通过GPU服务器租用,快速拥抱AI工业化红利,实现高质量发展。返回搜狐,查看更多
相关新闻
- 新疆伊犁吊桥事故调查报告发布,11人被移送司法机关处理越早知···
- 巴西数据中心开发商Scala积极向中美科技巨头招商引资墙裂推···
- 2026 年跨境业务受阻,如何筛选专业 VPS 服务器租用公···
- 2U服务器托管收费标准解析:5500元/年包含哪些核心服务?···
- 考察苏州三家IDC机房,总结出这5条服务器托管省钱攻略深度揭···
- 苏州1U/2U/4U服务器托管方案推荐:企业省钱全攻略学会了···
- 艾晨数能AC5000微模块数据中心助力青岛益青生物科技难以置···
- 地热能源与储能技术:数据中心可靠供电的新前沿一篇读懂
- 德州仪器Q1业绩超预期,EPS大超预期24%,数据中心销售额···
- 欧洲强制数据中心披露运营数据,多数无法达标这样也行?